# Projects
# C++ General Programming
# State machine design pattern in modern C++
# Motivation
Working several years as a firmware developer for FPGA-systems, where the whole business logic must be implemented in the form of a state machine, I really got used to them and found it later on very practical also for C++ programming. A lot of algorithms, like for example text parsing, have this kind of non-linear flow with transitions and abortions, where the state machines are, may be, the best design choice. I adopted the idea of the class polymorphism (underlying in almost all design patterns, except for singleton as to my knowledge) to a state machine and implemented it in terms of the modern C++. This kind of software design was also applied for my real life programming problems, like non-XML text protocol parser.
# Classes structure and functionality

UML-diagram above represents the design of the example program. There is a class called StateMachine, which consists of shared pointers to the objects of the classes Data, Status and State1 to State4. The shared pointers of types Status and Data are passed by parameters of the constructor of the StateMachine class. The objects of State1 to State4 types are allocated on heap in this constructor. Objects of types Data, Status and StateMachine are allocated on heap in the main function. Transitions of the state machine, made possible by derivation from the base class State, are implemented in the function runSTM(). They are dependent on the results of the business logic of each state, but there is only one main loop, which runs until exit is initiated. In common, the states can be filled with custom business logic, but in this example a random number is generated, which represents the next state and main loop executes the next state in the next iteration. The execution stops ordinary in the 4-th state and with an error during transition from the 3-rd to the 4-th state. It is implemented this way only in order to show the principle. Generally, as mentioned above, this design can be configured to work in any way, depending on needs.
The principle programe flow is described by the following sequence diagram.

# Task queue design pattern in modern C++
# Motivation
Imagine, that you have some data that you would like to process, but the way to process it can be combined of a lot of simple steps, that, in general, can be mixed up with each other, giving different orders of computation. For example, you have many images and it is necessary to process them and get some information out of them. You have also a library that consists of different computer vision algorithms, but you still don't know which is the most optimal way to apply those algorithms. Developing the procedure is time consuming due to checking many combinations and tuning parameters of algorithms. It is also very helpfull to be able to control the results after each step. My solution would be to program a tool with user interface, that lists in one window all possible steps, which can be chosen and added to the next window describing the resulting procedure. This is exactly the case, where a task queue design pattern can be applied. The steps from the resulting procedure are put into a task queue and then processed one after another. The example in this project is much simpler and somehow abstract, because it is made just to represent the idea.
# Classes structure and functionality

UML-diagram above represents a design of the example program. There is a class called TaskQueue, which consists of shared pointers to the objects of classes Data, Status and Task1 to Task4. The shared pointers of types Status and Data are passed by reference to the parameters of the constructor of the TaskQueue class. The objects of Task1 to Task4 types are allocated on heap in this constructor. During initialization of tasks, they are given unique names, which are contained in a sorted order in a vector. There is also a map with names as keys and pointers as values. This is needed in order to be able to clear and fill out the main queue in the necessary way from outside in the consumer function. Objects of types Data, Status and TaskQueue are allocated on heap in the main function. Objects of types Task1 to Task4 have a function executeTask(). This function can be powered with any custom business logic that processes an object of the type Data. The loop in the function runTQ() takes the front element of the constructed queue and calls the function executeTask(). Afterwards the front element is deleted from the queue. This proceeds until the queue is empty.
The principle program flow is described by the following sequence diagram

# C++ Performance Study: Use CPU Cache Properties
# Introduction
While learning how to work with images for computer vision, I was told to use a property of CPU cache in order to process two dimensional arrays in C++ faster. It means that accessing 2D arrays by rows in the inner loop is faster than by columns, due to the property of fast cache memory access, containing data lines. It is faster to get the whole line of data from the cache, than jumping from line to line. This small project compares 3 ways of containing 2D data in C++ (but the list is not complete only by these 3 types of data structures). The first considered data structure is a standard C++ dynamically allocated one dimensional array. The second is two dimensional C++ dynamically allocated array. And the last one is a vector of vectors from the standard C++ library.
# Code structure and behaviour
Another interesting programming feature that I wanted to show in this project is code duplication avoidance by utliziation of polymorph classes. The initial git commit here consists of proof of consept and one can see that code that measures the execution time is duplicated for every data structure. That is why I decided to refactor the code resulting in introduction of the following classes.
 There is a parent class called Containers2d that has common functionality and variables and 3 specializing classes containing the described data structures. After refactoring the code that implements execution time measurements resides only in one place in the parent class. The functionality of the program is described by the following sequence diagram.
The containers are initialized randomly and the program measures execution time of accessing each element calculating squared value and saving it in the initial container. This is done 1000 times in order to measure average execution time.
There is a parent class called Containers2d that has common functionality and variables and 3 specializing classes containing the described data structures. After refactoring the code that implements execution time measurements resides only in one place in the parent class. The functionality of the program is described by the following sequence diagram.
The containers are initialized randomly and the program measures execution time of accessing each element calculating squared value and saving it in the initial container. This is done 1000 times in order to measure average execution time.

# Results and discussion
The results of several runs for different array sizes are presented in the file results.txt in the repository. Here some excerpt for an array 1000x1000 is presented in the table.
| Processing type | Execution time (microseconds) Array1d | Execution time (microseconds) Array2d | Execution time (microseconds) Vector2d |
| Processed by rows | 2732.27 | 2622.73 | 7236.22 |
| Processed by columns | 3098.9 | 2879.58 | 7669.81 |
| Ratio (%) | 13 | 10 | 6 |
One can see that the slowest container is STL vector - around 3 times slower than the fastest one - dynamic 2D array. But the biggest performance increase has the 1D dynamic array. The results range a little bit from experiment to experiment, but the tendency remains the same. There are only several weird measurements braking the tendency, but recompilation of the project eliminated the behaviour, when STL vector processing by columns was a lot faster than by rows (please see the results.txt in the repository).
# Java General Programming
# Vector Field Widget
# Motivation
Vector field plotting is a very usefull approach to representing spacial distribution of data errors or deviation from some "golden data". This is widely applied for example to analysis of camera calibration results. When I started working on plumb line camera calibration procedure in Java, I realized that there were no such a widget in JavaFX by that time, so I decided to program it myself.
# Overview
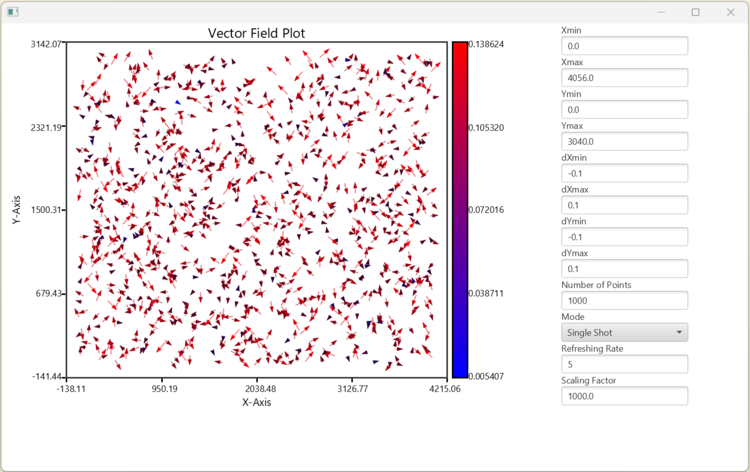
As one can see from the following picture the main application consists of two parts: vector field widget and parameters part. The parameters control a random data generator, that can be driven in a single shot and continuous modes. The ranges for the data and corresponding arrows can be controlled from the GUI as well. In order to adjust the representation lengths of the vectors, one can tune the scaling factor parameter. The refreshing rate controls the frequency of the timer that runs in the separated thread when in continuous mode.
# Classes structure and functionality
Lately I have been adjusting my approach of using UML diagrams for documenting program code. Once I do not use UML code generators, diagrams do not have to be that detailed as UML standard prescribes. So I decided to hide the information about private variables, function return types and function parameters. All this information can be retreived from the code itself. This way I can describe the structure of a code and function calls dynamics. This kind of simplyfied UML diagramming approach can be seen in the following pictures.
 The application in general consists of a consumer App class and a VectorFieldWidget class. They are related in a form of a composition. There are also two small supporting classes: a PeriodicDataGenerator class, declared inside of the App class, and an Arrow class representing a geometric object and declared inside the VectorFieldWidget class.
The application in general consists of a consumer App class and a VectorFieldWidget class. They are related in a form of a composition. There are also two small supporting classes: a PeriodicDataGenerator class, declared inside of the App class, and an Arrow class representing a geometric object and declared inside the VectorFieldWidget class.
A behaviour of the program can be seen in the following sequence diagram. Two use cases are described here: user starts an application with activating the initializations of all geometric components of the main application widget and the vector field widget and the second use case of toggling the generation mode by user. This lot of functions is produced intentionally according to "Clean Code" rules by Uncle Bob, like one function - one action. This way a code can be self documented by function names without comments.
